Anonimização de Dados
O que é Anonimização de Dados?
A anonimização de dados é o processo pelo qual os dados são modificados de forma que não possam ser vinculados a uma pessoa específica. Isso é alcançado eliminando ou modificando as informações pessoalmente identificáveis (IPI), como nome, endereço, número de segurança social e outros identificadores específicos. As organizações ainda podem obter insights e analisar sem revelar as identidades dos indivíduos por meio da anonimização de dados.
Conceito e Propósito
A anonimização de dados é definida como o ato de alterar ou transformar os dados de maneira que seja impossível para os dados serem vinculados a uma pessoa específica. O objetivo da anonimização é proteger a privacidade dos sujeitos dos dados, impedindo sua identificação a partir dos dados. Isso é especialmente crítico em casos onde as informações são confidenciais, como arquivos médicos, operações financeiras ou informações de clientes. Através da anonimização dos dados, as organizações podem extrair informações úteis e analisá-las garantindo que a privacidade não seja comprometida.
O processo de anonimização de dados significa a eliminação ou substituição de qualquer informação pessoalmente identificável que possa identificar potencialmente um indivíduo específico. Isso engloba tudo, desde nomes, endereços, números de segurança social, números de telefone, endereços de e-mail e quaisquer outros identificadores únicos. Os dados são tornados indistinguíveis ao remover os identificadores, e a conexão com os indivíduos reais é cortada. No entanto, a anonimização de dados não garante completamente o anonimato, dado a possibilidade de re-identificação ao aplicar várias técnicas.
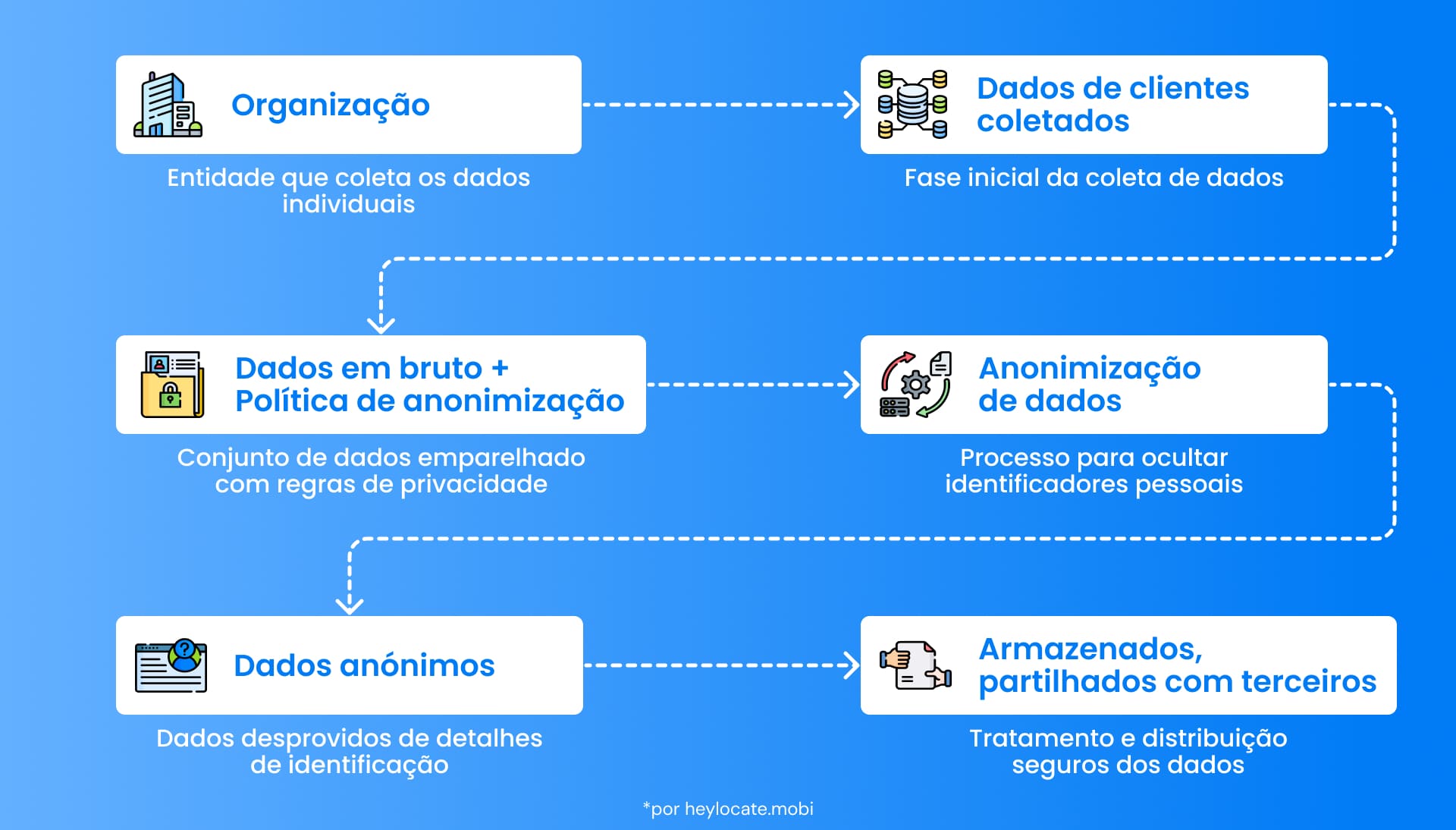
Visão Geral do Processo de Anonimização
Frameworks regulatórios como o Regulamento Geral sobre a Proteção de Dados (GDPR) na União Europeia e o Ato de Portabilidade e Responsabilidade de Seguro de Saúde (HIPAA) nos Estados Unidos são projetados para fornecer diretrizes específicas sobre a anonimização de dados.
A anonimização de dados é fundamental para transferências e análises de dados internacionais. Ela permite que as organizações coletem, analisem e troquem informações sem violar as normas de privacidade.
A anonimização é especialmente crucial para registros médicos, pois eles contêm informações pessoais que podem causar danos enormes às pessoas se forem divulgadas. Portanto, é necessário remover todas as informações identificáveis, inclusive nomes de pacientes, endereços, números de previdência social e números de registros médicos. Além disso, indicadores indiretos, como idade, sexo e algumas doenças médicas, também podem ser generalizados ou suprimidos para garantir a privacidade.
Riscos Potenciais da Anonimização
Um dos principais perigos da anonimização é o risco de reidentificação, em que um conjunto de dados anônimos pode ser desanonimizado e conectado novamente ao indivíduo ao qual pertence.
A desanonimização de dados pode abranger diferentes recursos, como
- a vinculação de dados requer a correspondência e a vinculação de vários conjuntos de dados para identificar identificadores comuns para reidentificar dados anônimos;
- os ataques de inferência se baseiam na inferência de informações confidenciais sobre indivíduos devido a padrões e correlações no conjunto de dados;
- as informações externas são chamadas de conhecimento de fundo, o que leva à identificação de um indivíduo pelos dados.
Organizações frequentemente utilizam a pseudonimização como uma proteção adicional contra esses riscos. A pseudonimização envolve substituir informações autênticas com pseudônimos ou marcadores de posição para que se torne mais difícil reconhecer indivíduos pelo nome. Métodos de pseudonimização, incluindo tokenização e criptografia, são frequentemente usados para proteger a privacidade dos dados pessoais durante a análise.
Técnicas de Anonimização de Dados
A anonimização de dados pode ser alcançada de várias maneiras, todas projetadas para alcançar o propósito específico de garantir a privacidade. Os métodos mais comuns de anonimização são generalização, supressão, anatomização, permutação e perturbação.
| Tipo de anonimização | Descrição da técnica | Exemplo |
|---|---|---|
| Mascaramento de dados | Oculta valores originais com valores modificados | Substituir caracteres sensíveis em um texto por símbolos como “*” ou “x”, por exemplo, mascarar parte de um número de previdência social em registros de clientes |
| Pseudonimização | Substitui identificadores privados por pseudônimos | Troca de “John Smith” por “Mark Spencer” em um conjunto de dados para manter a privacidade e, ao mesmo tempo, preservar a utilidade dos dados para análise |
| Generalização | Substitui informações detalhadas por categorias mais amplas | Modificação de idades específicas em faixas etárias, como transformar “25” em “20-30”, para tornar anônimos os dados de idade e, ao mesmo tempo, manter a utilidade para a análise demográfica |
| Troca de dados (permutação) | Reorganiza os valores dos dados em um conjunto de dados | O embaralhamento ou permutação de valores de atributos, como data de nascimento entre linhas, interrompe o vínculo direto com os indivíduos |
| Perturbação de dados | Adiciona ruído aleatório ou pequenas alterações aos dados | O arredondamento de números, como o ajuste de valores de renda, impede a identificação exata |
| Dados sintéticos | Gera dados artificiais com base em padrões de dados reais | Usado no lugar de conjuntos de dados confidenciais para pesquisa ou treinamento de modelos de aprendizado de máquina sem comprometer a privacidade do indivíduo |
Integrando diferentes técnicas e implementando mecanismos de privacidade, as organizações podem obter os dados necessários anonimizados para reter a utilidade dos dados para fins de pesquisa.
Referências
- ISO 25237:2017 Health informatics – Pseudonymization. ISO. 2017. p. 7.
- “Data anonymization”. The Free Medical Dictionary.
- “De-anonymization”. Whatis.com.
- “Opinion 05/2014 on Anonymisation Techniques” (PDF). EU Commission. 10 de abril de 2014.
- Data anonymization – Wikipedia
- What is Data Anonymization | Pros, Cons & Common Techniques | Imperva
- What is Data Anonymization | Techniques, Pros, Cons, and Use Cases