Data Anonymization
What is Data Anonymization?
Data anonymization is the process where data is modified so that it cannot be linked to a particular person. This is accomplished by eliminating or modifying the personally identifiable information (PII) like name, address, social security number, and other specific identifiers. Organizations may still gain insights and analyze without revealing the identities of individuals through anonymizing data.
Concept and Purpose
Anonymization of data is defined as the act of changing or transforming data so that it is impossible for the data to be linked to a particular person. Anonymization aims to protect data subjects’ privacy by inhibiting their identification from the data. This is especially critical in cases where the information is confidential, such as medical files, financial operations, or customer information. Through anonymization of the data, the organizations can still extract useful information and analyze it while ensuring that privacy is not compromised.
The process of data anonymization means the deleting or replacing of any personally identifiable information that could potentially identify a specific individual. This encompasses everything from names, addresses, social security numbers, phone numbers, email addresses, and any other unique identifiers. The data is rendered indistinguishable by removing the identifiers, and the connection to the actual individuals is severed. Nevertheless, data anonymization does not completely ensure anonymity, given the possibility of re-identification by applying various techniques.
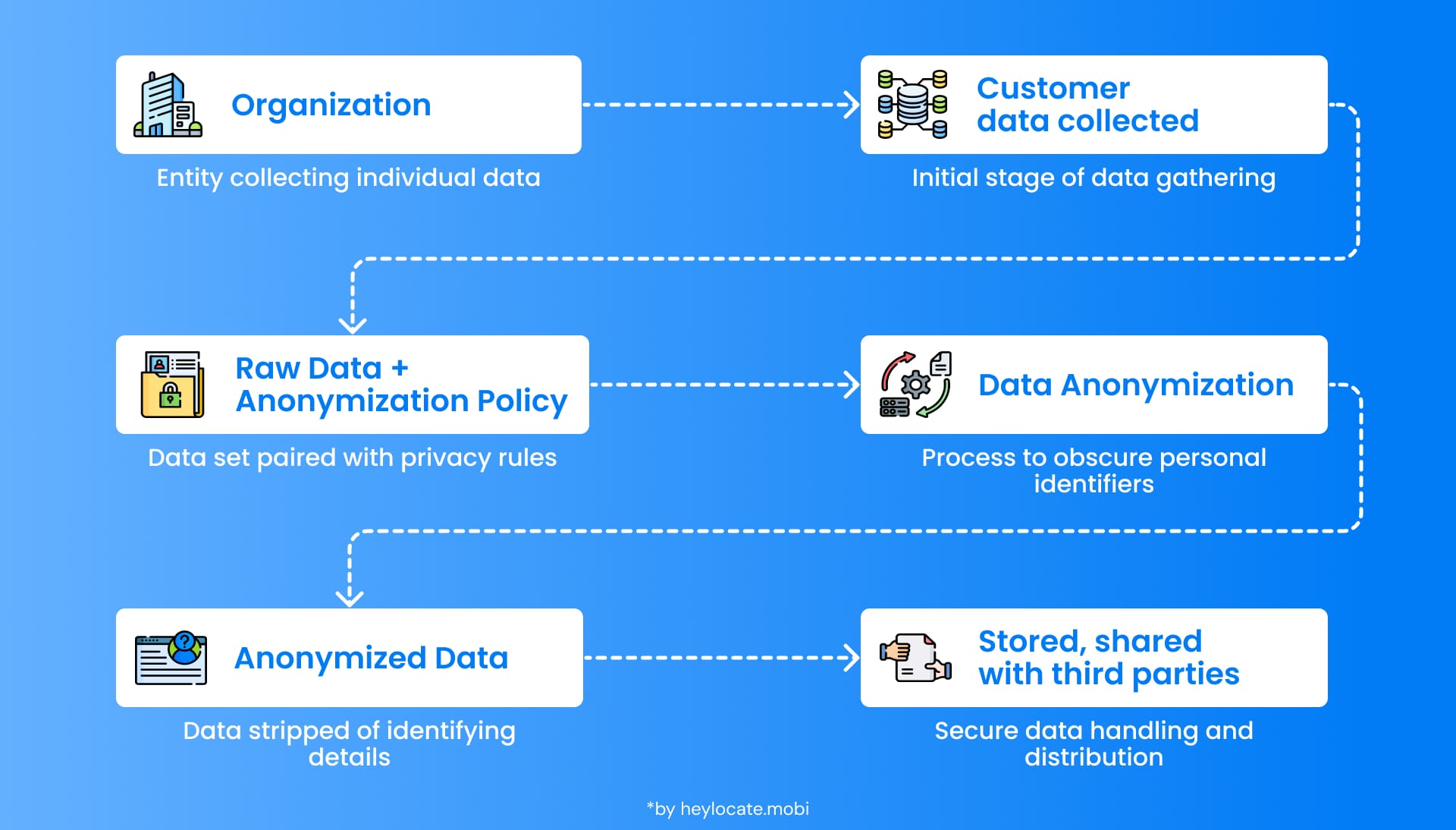
Overview of the Anonymization Process
Regulatory frameworks like the General Data Protection Regulation (GDPR) in the European Union and the Health Insurance Portability and Accountability Act (HIPAA) in the United States are designed to provide specific guidelines on data anonymization.
Data anonymization is key for cross-border data transfers and analytics. It enables organizations to collect, analyze and exchange information without violating privacy regulations.
Anonymization is especially crucial for medical records, as they hold personal information that can cause massive damage to people if disclosed. Thus, it is necessary to remove all identifiable information, including patient names, addresses, social security numbers and medical record numbers. Furthermore, indirect indicators, like age, sex, and a few medical diseases could be generalized or suppressed to ensure privacy as well.
Potential Risks of Anonymization
One of the major dangers in anonymization is the risk of re-identification, where an anonymous data set can be de-anonymized and connected back to the individual it belongs to.
De-anonymizing data can embrace different capabilities, such as,
- data linkage requires matching and linking multiple datasets to identify common identifiers to re-identify anonymized data;
- inference attacks are based on inferring sensitive information about individuals due to patterns and correlations in the dataset;
- external information is referred to as background knowledge, which leads to identifying an individual by the data.
Organizations often utilize pseudonymization as an additional shield against these risks. Pseudonymization involves substituting authentic information with pseudonyms or placeholders so that it becomes harder to recognize individuals by name. Pseudonymization methods, including tokenization and encryption, are often used to protect personal data privacy during the analysis.
Techniques of Data Anonymization
Data anonymization can be accomplished in several ways, all designed to achieve the specific purpose of ensuring privacy. The most common anonymization methods are generalization, suppression, anatomization, permutation, and perturbation.
| Type of Anonymization | Technique Description | Example |
|---|---|---|
| Data Masking | Conceals original values with modified ones | Replacing sensitive characters in a text with symbols like “*” or “x”, e.g., masking part of a social security number in customer records |
| Pseudonymization | Replaces private identifiers with pseudonyms | Swapping “John Smith” with “Mark Spencer” in a dataset to maintain privacy while preserving data utility for analysis |
| Generalization | Replaces detailed information with broader categories | Modifying specific ages into age ranges, like turning “25” into “20-30”, to anonymize age data while retaining usefulness for demographic analysis |
| Data Swapping (Permutation) | Rearranges data values within a dataset | Shuffling or permuting attribute values such as date of birth between rows disrupt the direct link to individuals |
| Data Perturbation | Adds random noise or slight alterations to data | Rounding numbers, like adjusting income figures slightly prevent exact identification |
| Synthetic Data | Generates artificial data based on real data patterns | Used in place of sensitive datasets for research or training machine learning models without compromising individual privacy |
By integrating different techniques and implementing privacy mechanisms, organizations can get the required data anonymized to retain the usefulness of data for research purposes.
References
- ISO 25237:2017 Health informatics – Pseudonymization. ISO. 2017. p. 7.
- “Data anonymization”. The Free Medical Dictionary.
- “De-anonymization”. Whatis.com.
- “Opinion 05/2014 on Anonymisation Techniques” (PDF). EU Commission. 10 April 2014.
- Data anonymization – Wikipedia
- What is Data Anonymization | Pros, Cons & Common Techniques | Imperva
- What is Data Anonymization | Techniques, Pros, Cons, and Use Cases