Datenanonymisierung
Was ist Datenanonymisierung?
Datenanonymisierung ist der Prozess, bei dem Daten so verändert werden, dass sie nicht mehr mit einer bestimmten Person verknüpft werden können. Dies wird erreicht, indem persönlich identifizierbare Informationen (PII) wie Name, Adresse, Sozialversicherungsnummer und andere spezifische Kennungen entfernt oder modifiziert werden. Organisationen können weiterhin Einsichten gewinnen und analysieren, ohne die Identität der Einzelpersonen durch Datenanonymisierung preiszugeben.
Konzept und Zweck
Die Anonymisierung von Daten wird als der Akt des Änderns oder Transformierens von Daten definiert, so dass es unmöglich ist, die Daten mit einer bestimmten Person zu verknüpfen. Das Ziel der Anonymisierung besteht darin, die Privatsphäre der Datensubjekte zu schützen, indem ihre Identifizierung aus den Daten verhindert wird. Dies ist besonders kritisch in Fällen, in denen die Informationen vertraulich sind, wie medizinische Akten, Finanztransaktionen oder Kundeninformationen. Durch die Anonymisierung der Daten können Organisationen nützliche Informationen extrahieren und analysieren, während sichergestellt wird, dass die Privatsphäre nicht kompromittiert wird.
Der Prozess der Datenanonymisierung bedeutet das Löschen oder Ersetzen jeglicher persönlich identifizierbarer Informationen, die potenziell eine spezifische Person identifizieren könnten. Dies umfasst alles von Namen, Adressen, Sozialversicherungsnummern, Telefonnummern, E-Mail-Adressen und anderen einzigartigen Kennungen. Die Daten werden durch Entfernen der Kennungen ununterscheidbar gemacht, und die Verbindung zu den tatsächlichen Personen wird unterbrochen. Dennoch garantiert die Datenanonymisierung nicht vollständig die Anonymität, angesichts der Möglichkeit der Re-Identifikation durch Anwendung verschiedener Techniken.
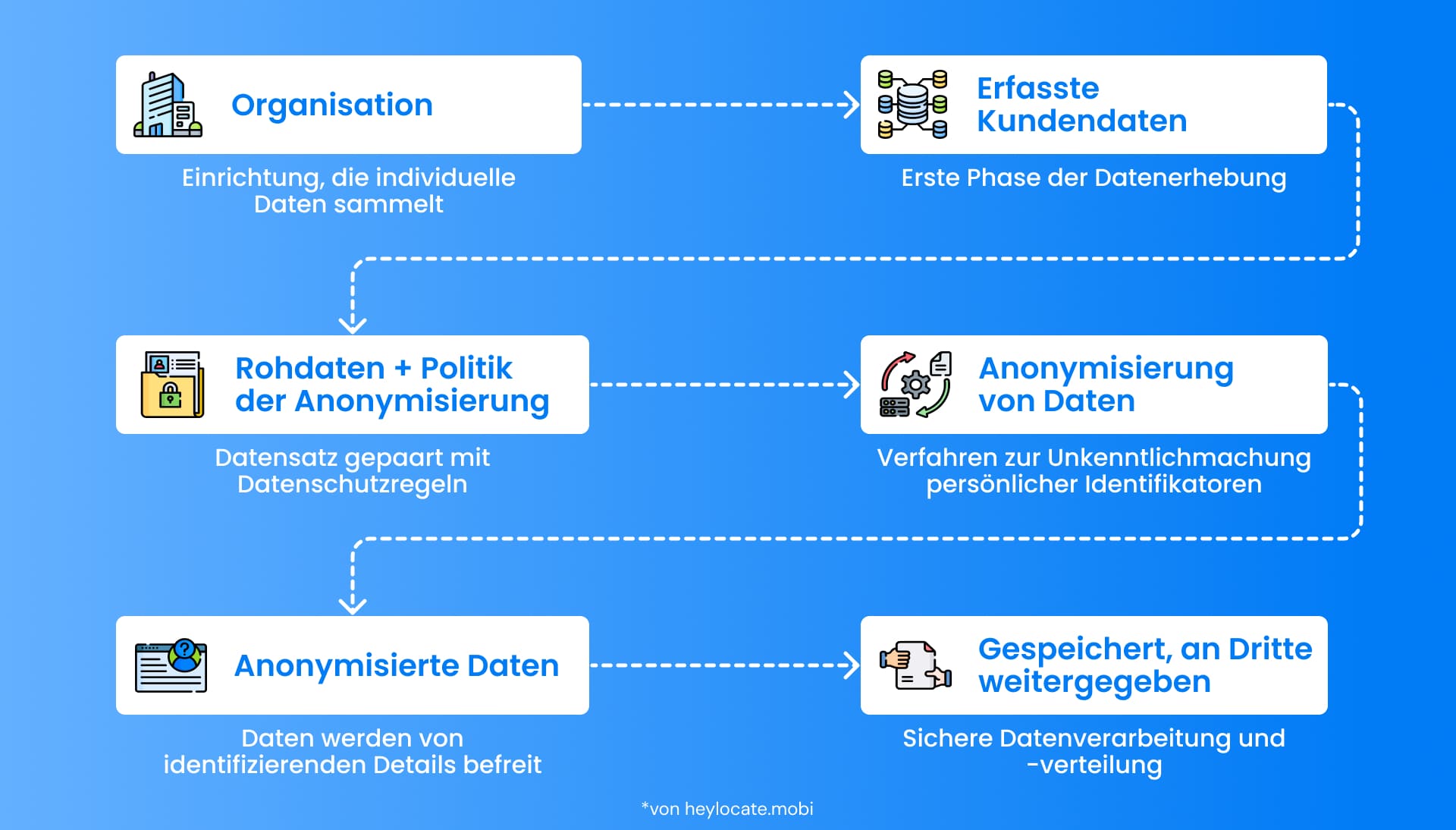
Übersicht über den Anonymisierungsprozess
Regulatorische Rahmenwerke wie die Allgemeine Datenschutzverordnung (DSGVO) in der Europäischen Union und der Health Insurance Portability and Accountability Act (HIPAA) in den Vereinigten Staaten sind darauf ausgelegt, spezifische Richtlinien zur Datenanonymisierung vorzugeben.
Die Anonymisierung von Daten ist der Schlüssel für grenzüberschreitende Datenübertragungen und Analysen. Sie ermöglicht es Unternehmen, Informationen zu sammeln, zu analysieren und auszutauschen, ohne gegen Datenschutzbestimmungen zu verstoßen.
Die Anonymisierung ist vor allem für medizinische Daten von entscheidender Bedeutung, da sie persönliche Informationen enthalten, die bei Offenlegung massiven Schaden anrichten können. Daher ist es notwendig, alle identifizierbaren Informationen zu entfernen, einschließlich Patientennamen, Adressen, Sozialversicherungsnummern und Krankenaktennummern. Außerdem könnten indirekte Indikatoren wie Alter, Geschlecht und einige Krankheiten verallgemeinert oder unterdrückt werden, um die Privatsphäre zu schützen.
Potenzielle Risiken der Anonymisierung
Eine der größten Gefahren bei der Anonymisierung ist das Risiko der Re-Identifizierung, bei der ein anonymer Datensatz de-anonymisiert und mit der Person, zu der er gehört, in Verbindung gebracht werden kann.
Die Anonymisierung von Daten kann verschiedene Möglichkeiten umfassen, wie z. B,
- Datenverknüpfung erfordert den Abgleich und die Verknüpfung mehrerer Datensätze, um gemeinsame Identifikatoren zu ermitteln und anonymisierte Daten wieder zu identifizieren;
- Inferenzangriffe basieren auf der Ableitung sensibler Informationen über Personen aufgrund von Mustern und Korrelationen im Datensatz;
- externe Informationen werden als Hintergrundwissen bezeichnet, das zur Identifizierung einer Person anhand der Daten führt.
Organisationen nutzen häufig die Pseudonymisierung als zusätzlichen Schutz gegen diese Risiken. Die Pseudonymisierung beinhaltet das Ersetzen authentischer Informationen durch Pseudonyme oder Platzhalter, so dass es schwieriger wird, Personen anhand ihres Namens zu erkennen. Pseudonymisierungsmethoden, einschließlich Tokenisierung und Verschlüsselung, werden oft verwendet, um die Privatsphäre persönlicher Daten während der Analyse zu schützen.
Techniken der Datenanonymisierung
Die Datenanonymisierung kann auf verschiedene Weisen erreicht werden, alle mit dem spezifischen Ziel, die Privatsphäre zu gewährleisten. Die gängigsten Anonymisierungsmethoden sind Generalisierung, Unterdrückung, Anatomisierung, Permutation und Perturbation.
| Art der Anonymisierung | Technik Beschreibung | Beispiel |
|---|---|---|
| Maskierung von Daten | Verschleierung von Originalwerten durch veränderte Werte | Ersetzen sensibler Zeichen in einem Text durch Symbole wie „*“ oder „x“, z. B. Maskierung eines Teils einer Sozialversicherungsnummer in Kundendatensätzen |
| Pseudonymisierung | Ersetzt private Identifikatoren durch Pseudonyme | Ersetzen von „John Smith“ durch „Mark Spencer“ in einem Datensatz, um die Privatsphäre zu wahren und gleichzeitig den Nutzen der Daten für die Analyse zu erhalten |
| Verallgemeinerung | Ersetzt detaillierte Informationen durch umfassendere Kategorien | Ändern bestimmter Altersangaben in Altersbereiche, z. B. „25“ in „20-30“, um Altersdaten zu anonymisieren und gleichzeitig die Nützlichkeit für demografische Analysen zu erhalten |
| Datenvertauschung (Permutation) | Neuordnung von Datenwerten innerhalb eines Datensatzes | Das Mischen oder Vertauschen von Attributwerten, wie z. B. des Geburtsdatums, zwischen Zeilen unterbricht die direkte Verbindung zu Personen |
| Daten-Störungen | Hinzufügen von zufälligem Rauschen oder leichten Änderungen an Daten | Das Runden von Zahlen, z. B. das leichte Anpassen von Einkommenszahlen, verhindert eine genaue Identifizierung |
| Synthetische Daten | Erzeugt künstliche Daten auf der Grundlage realer Datenmuster | Sie werden anstelle sensibler Datensätze für Forschungszwecke oder zum Trainieren von Modellen des maschinellen Lernens verwendet, ohne die Privatsphäre des Einzelnen zu gefährden |
Durch die Integration verschiedener Techniken und die Implementierung von Datenschutzmechanismen können Organisationen die erforderlichen Daten anonymisieren, um die Nützlichkeit der Daten für Forschungszwecke zu erhalten.
Verweise
- ISO 25237:2017 Health informatics – Pseudonymization. ISO. 2017. p. 7.
- “Data anonymization”. The Free Medical Dictionary.
- “De-anonymization”. Whatis.com.
- “Opinion 05/2014 on Anonymisation Techniques” (PDF). EU Commission. 10 April 2014.
- Data anonymization – Wikipedia
- What is Data Anonymization | Pros, Cons & Common Techniques | Imperva
- What is Data Anonymization | Techniques, Pros, Cons, and Use Cases